When the Cloud Goes Down: A Day That Made Me Rethink My Setup
Posted on November 18, 2025by Nish
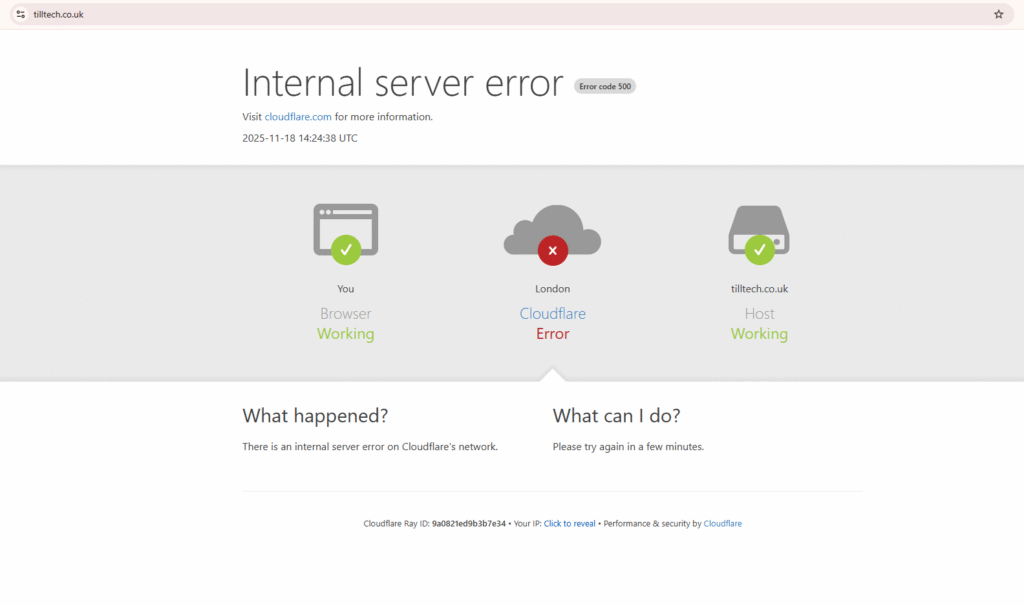
Today was one of those days where everything that normally “just works” decides to take a vacation. Cloudflare had a pretty big outage, and suddenly all my websites were unreachable. The funny part? Everything behind Cloudflare was perfectly fine. My home server was running. My Google Cloud Run failover was running.
I was down not because my infrastructure failed, but because the one service sitting in front of everything did.
It reminded me of the only time my home setup ever went down — a power outage that lasted a few hours. That outage is what pushed me to move some of my hosting into the cloud in the first place. I didn’t want to rely only on my home network where a single thunderstorm could ruin someone’s day. At the same time, I didn’t want to lose the insane speed and one-time hardware cost advantage that self-hosting gives.
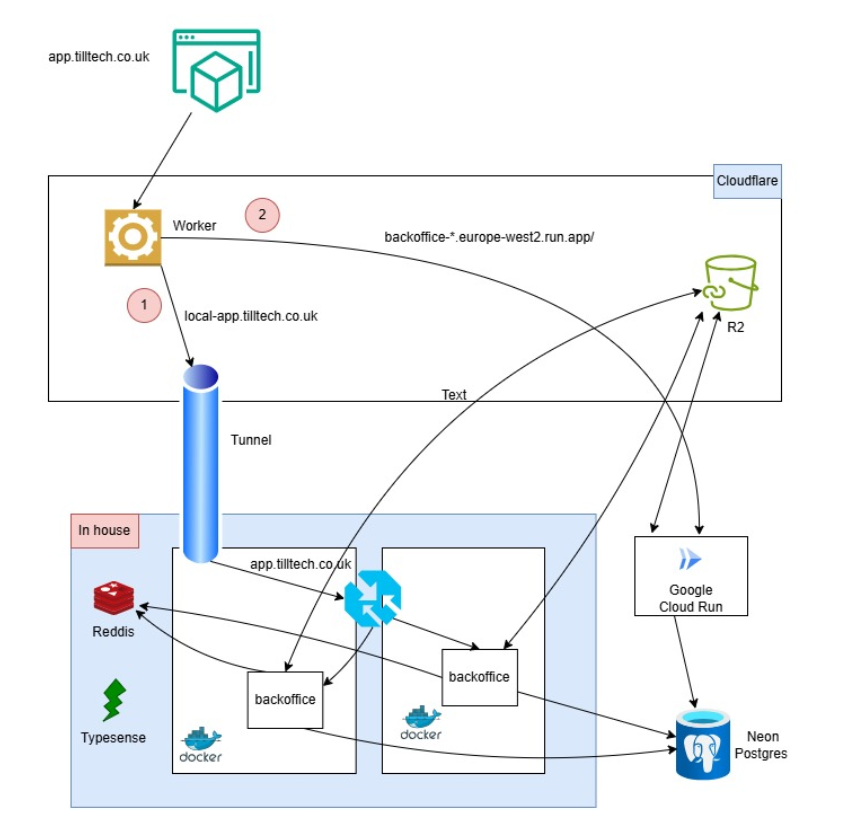
So I built what I thought was the perfect hybrid setup: Cloudflare Worker routes traffic → primarily to my home network If my home network looks unhealthy → route to Google Cloud Run
This was genius (I thought). I’d pay Google Cloud Run only if my home server went down. Cloudflare gets me global routing, and Cloud Run is my safety net.
But today proved something important:
A highly-available system can still fail if it depends on a single gatekeeper.
In other words: even if my servers are working beautifully, if Cloudflare — the “bouncer” at the door — collapses, nobody gets in.
What “Highly Available” Actually Means (and What It Doesn’t)
“Highly available” means the system stays up all the time. No. Not even close.
True high availability isn’t about eliminating downtime. It’s about minimising how much downtime you suffer and making the system resilient enough to keep running even if one or two parts fall down dramatically.
Even Amazon, Google, Cloudflare, Azure — the companies with unlimited money, unlimited engineers, and unlimited caffeine — still have outages.
So for the rest of us mere mortals, the real goal is:
✔ Reduce blast radius
✔ Add redundancy in places that matter
✔ Avoid single points of failure
✔ Balance cost vs resilience
✔ Accept that 100% uptime is a myth
And—important—look at your own architecture with brutal honesty.
I didn’t want to admit it, but in my “super smart” routing setup, I created a big shiny single point of failure: Cloudflare Workers. If Cloudflare dies, everything dies.
Today proved it.
How I Recommend Designing for High Availability
This isn’t a universal guide. It’s simply what I personally learned from today’s disaster and what I recommend to anyone building a website that should stay online most of the time.
Here we go:
1. Avoid putting a single provider in the request path
If all traffic must pass through one company’s infrastructure (Cloudflare, Fastly, Vercel, whatever), then that company is your actual single point of failure.
Even if:
Your server is up
Your database is up
Your failover system is up
…you can still be down.
Try to ensure you have at least one way to serve traffic without going through the same dependency.
2. Use redundancy at the DNS level, not just inside one provider
Cloudflare DNS is very reliable, but if their proxy layer fails, your site still appears down. Moving critical routing decisions to something like Route53 or NS1 makes your setup more resilient because DNS-only providers have fewer ways to fail.
DNS failover → route directly to home or to cloud No scripts, no proxies, no workers in the hot path.
Small changes can massively improve uptime.
3. Don’t chase “100% uptime.” It doesn’t exist.
Even if you spend thousands per month, you’re still vulnerable to:
Network outages
Upstream outages
Regional service failures
Provider-wide incidents
Human mistakes
Misconfigurations
Random chaos
The real question is:
How much downtime can you tolerate and how much are you willing to pay to reduce it?
That’s the heart of high availability: a cost–benefit analysis, not superhero engineering.
4. Build failover based on your own risk profile, not someone else’s
For example, I decided:
My home server = fast, cheap, always-on
Cloud Run = pay-per-use backup
DNS failover = cheap reliability
Cloudflare = CDN/security, not a mandatory gateway
Your choices might be different, and that’s okay — high availability isn’t a template. It’s a strategy.
Final Takeaway From Today
Today’s Cloudflare outage didn’t just ruin my morning — it also helped me see the flaws in my own architecture.
And honestly, that’s a good thing. High availability is a journey, not a checkbox. Every outage is a lesson waiting to be written about (like this one).
If your system goes down today, don’t think “I failed.” Think:
“What single dependency brought the whole thing down, and how do I reduce that dependency next time?”
That’s the real mindset behind highly available systems.
And if you ever catch yourself thinking “My setup is perfect,” just wait. The universe will test that confidence.



Leave a Reply